[Jan 2023] -- Our work on sequencing policies for long-horizon manipulation has been accepted to ICRA 2023!
..Education
Ph.D in Computer Science
Department of Computer Science, Stanford University
Sep 2021 - Mar 2026 | Stanford, CA Deployment-Time Reliability of Learned Robot Policies | Dissertation | Defense School of Engineering Fellowship 2 x TA for Principles of Robot Autonomy 1 (2023, 2024) 1 x TA for Principles of Robot Autonomy 2 (2025) 1 x TA for Test of AI & Emerging Technologies (2026); in service of the US Air Force (news)
B.A.Sc in Engineering Science, Robotics
Faculty of Applied Science and Engineering, University of Toronto
Sep 2016 - May 2021 | Toronto, ON Contextual Graph Representations for Task-Driven 3D Perception and Planning | Thesis President's Scholarship Program NSERC Undergraduate Research Award Dean's Honour List - 2018-2021
..Research
Papers and preprints are ordered by recency. Representative works are highlighted in green.
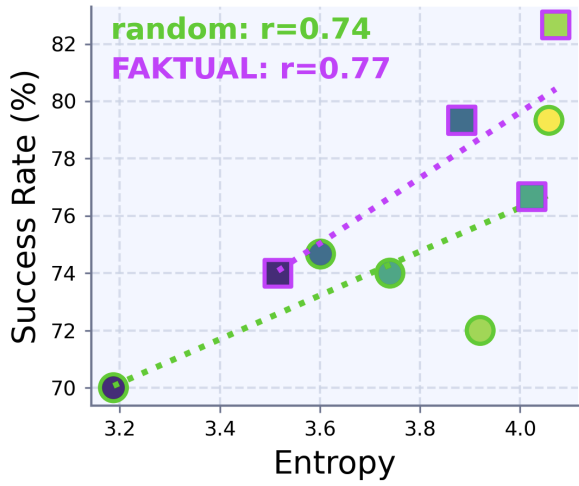
Dataset diversity drives success in robot imitation learning, but is hard to quantify over structured, variable-length, and high-dimensional trajectories.
We introduce FAKTUAL, a model-free data curation algorithm that uses signature kernel-based entropy to estimate the relative diversity of individual demonstrations.
LLMs and VLMs are increasingly deployed in robotics but remain vulnerable to jailbreaking attacks that may drive physically harmful behaviors in the real world.
We introduce J-DAPT, a real-time robotics jailbreak detector that adapts to prevent novel threats in data-limited regimes via multimodal domain adaptation.
In robot imitation learning, policy performance is tightly coupled with the quality and composition of the demonstration data.
We present CUPID, a data curation method that uses influence functions to estimate the causal impact of each demonstration on a policy's closed-loop performance.
Vision-Language-Action (VLA) models have demonstrated remarkable capabilities in visuomotor control, yet ensuring their robustness in unstructured real-world environments remains a persistent challenge.
In this paper, we investigate inference-time scaling as means to enhance VLA robustness and generalization.
Foundation models can reason about appropriate safety interventions in hazardous out-of-distribution scenarios beyond a robot's training data.
We present FORTRESS, a framework that generates and reasons about semantically safe fallback strategies in real time to prevent out-of-distribution failures.
Points2Plans: From Point Clouds to Long-Horizon Plans with Composable Relational Dynamics Yixuan Huang, Christopher Agia, Jimmy Wu, Tucker Hermans, Jeannette Bohg IEEE International Conference on Robotics and Automation (ICRA), 2025 | Atlanta, US
arXiv / Project Site / Code CoRL 2024 Workshop on Learning Effective Abstractions for Planning (Oral Presentation)
How can we plan to solve unseen, long-horizon tasks from a single, partial-view point cloud of the scene, and can we do so without access
to long-horizon training data? Points2Plans leverages transformer-based relational dynamics to learn the symbolic and geometric effects of
robot skills, then compose the skills at test time to generate a long-horizon symbolic and geometric plan.
Unpacking Failure Modes of Generative Policies: Runtime Monitoring of Consistency and Progress Christopher Agia, Rohan Sinha, Jingyun Yang, Zi-ang Cao, Rika Antonova, Marco Pavone, Jeannette Bohg Conference on Robot Learning (CoRL), 2024 | Munich, DE
arXiv / Project Site / YouTube / Code / X CoRL 2024 Workshop on Safe and Robust Robot Learning (Oral Presentation) RSS 2024 Workshop: Towards Safe Autonomy: Emerging Requirements, Definitions, and Methods
Robot behavior policies trained via imitation learning are prone to failure under conditions that deviate from their training data.
In this work, we present Sentinel, a runtime monitor that detects unknown failures (requiring no data of failures) of generative robot policies at deployment time.
Text2Interaction: Establishing Safe and Preferable Human-Robot Interaction Jakob Thumm, Christopher Agia, Marco Pavone, Matthias Althoff Conference on Robot Learning (CoRL), 2024 | Munich, DE
arXiv / Project Site / YouTube / Code CoRL 2024 Workshop on Language and Robot Learning: Language as an Interface
How can we integrate human preferences into robot plans in a zero-shot manner, i.e., without requiring tens of thousands of data points
of human feedback? We propose Text2Interaction, a planning framework that invokes large language models to generate a task plan, motion preferences as Python code,
and parameters of a safe controller.
How can we mitigate the computational expense and latency of LLMs for real-time anomaly detection and reactive planning?
We propose a two-stage reasoning framework, whereby fast a LLM embedding model flags potential observational anomalies
while a slower generative LLM assesses the safety-criticality of flagged anomalies and selects a safety-preserving fallback plan.
We introduce DROID (Distributed Robot Interaction Dataset), a diverse robot manipulation dataset with
76k demonstration trajectories (or 350 hours of interaction data), collected across 564 scenes and 86
tasks by 50 data collectors in North America, Asia, and Europe over the course of 12 months. We demonstrate
that training with DROID leads to policies with higher performance and improved generalization ability.
Future space exploration missions to unknown worlds will require robust reasoning, planning, and decision-making capabilities,
enabled by the right choice of onboard models. In this work, we aim to understand what onboard models a spacecraft needs for fully autonomous space exploration.
Open X-Embodiment: Robotic Learning Datasets and RT-X Models
Open X-Embodiment Collaboration
IEEE International Conference on Robotics and Automation (ICRA), 2024 (Best Paper) | Yokohama, JP
arXiv / Project Site / Blogpost / Code
Conventionally, robotic learning methods train a separate model for every application, every robot, and even every environment.
Can we instead train “generalist” X-robot policy that can be adapted efficiently to new robots, tasks, and environments?
Pretrained large language models can be readily used to obtain high-level robot plans from natural lanugage instructions, but should these
plans be executed without verifying them on the geometric-level? We propose Text2Motion, a language-based planner that tests if
LLM-generated plans (a) satisfy user instructions and (b) are geometric feasibility prior to executing them.
System-level failures are not due to failures of any individual component of the autonomy stack but
system-level deficiencies in semantic reasoning. Such edge cases, dubbed semantic anomalies,
are simple for a human to disentangle yet require insightful reasoning. We introduce a runtime monitor based
on large language models to recognize failure-inducing semantic anomalies.
Solving sequential manipulation tasks requires coordinating geometric dependencies between actions.
We develop a scalable framework for training skills independently, and then combine the skills at planning
time to solve unseen long-horizon tasks. Planning is formulated as a maximization problem over the expected
success of the skill sequence, which we demonstrate is well-approximated by the product of Q-values.
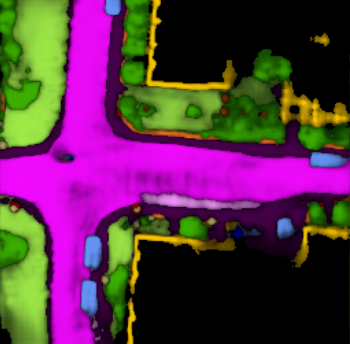
3D Scene Graphs (3DSGs) are informative abstractions of our world that unify symbolic, semantic, and metric scene representations.
We present a benchmark for robot task planning over large 3DSGs and evaluate classical and learning-based planners;
showing that real-time planning requires 3DSGs and planners to be jointly adapted to better exploit 3DSG hierarchies.
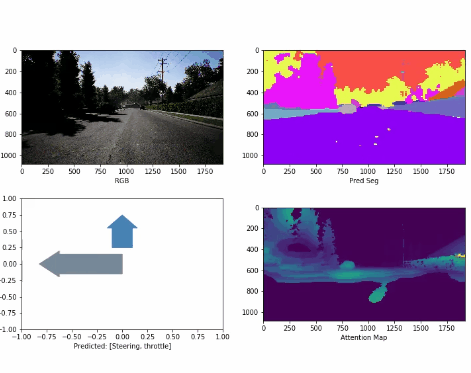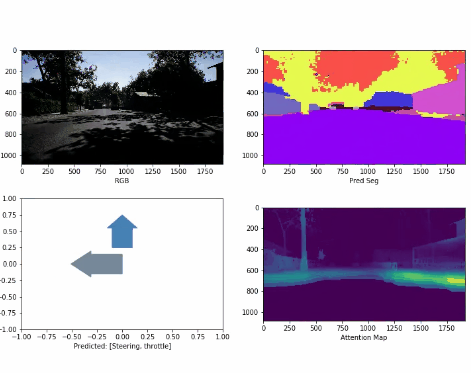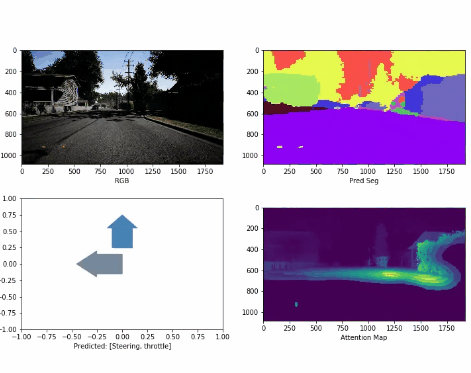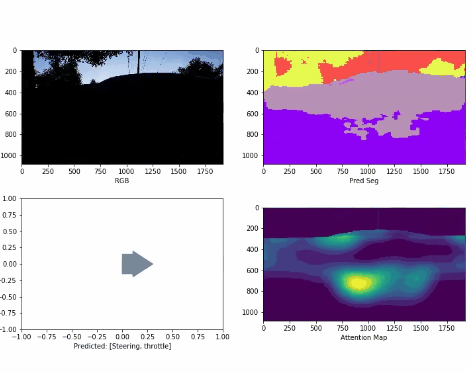
Latent Attention Augmentation for Robust Autonomous Driving Policies Ran Cheng*, Christopher Agia*, David Meger, Florian Shkurti, Gregory Dudek IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2021 | Prague, CZ
PDF / IEEExplore
Pretraining visual representations for robotic reinforcement learning can improve sample efficiency and policy performance.
In this paper, we take an alternate approach and propose to augment the state embeddings of a self-driving agent with
attention in the latent space, accelerating the convergence of Actor-Critic algorithms.
Deep Reinforcement Learning is effective for learning robot navigation policies in rough terrain and cluttered simulated environments.
In this work, we introduce a series of techniques that are applied in the policy learning phase to enhance transferability to real-world domains.
Lightweight Semantic-aided Localization with Spinning LiDAR Sensor
Yuan Ren, Bingbing Liu, Ran Cheng, Christopher Agia IEEE Transactions on Intelligent Vehicles (T-IV), 2021
PDF / IEEExplore
How can semantic information be leveraged to improve localization accuracy in changing environments? We present a robust LiDAR-based localization
algorithm that exploits both semantic and geometric properties of the scene with an adaptive fusion strategy.
S3CNet: A Sparse Semantic Scene Completion Network for LiDAR Point Clouds Ran Cheng*, Christopher Agia*, Yuan Ren, Bingbing Liu Conference on Robot Learning (CoRL), 2020 | Cambridge, US
arXiv / YouTube / Demo
Small-scale semantic reconstruction methods have had little success in large outdoor scenes as a result of exponential increases in sparsity,
and a computationally expensive design. We propose a sparse convolutional network architecture based on the Minkowski Engine,
achieving state-of-the-art results for semantic scene completion in 2D/3D space from LiDAR point clouds.
Direct methods are able to track motion with considerable long-term accuracy. However, scale inconsistent estimates arise from random or unit depth initialization.
We integrate dense depth prediction with the Direct Sparse Odometry system to accelerate convergence in the windowed bundle-adjustment and promote estimates with consistent scale.
Theses / Dissertations
Deployment-Time Reliability of Learned Robot Policies Christopher Agia, Marco Pavone, Jeannette Bohg Department of Computer Science, Stanford University, 2026 | Stanford, US
arXiv / YouTube
This dissertation investigates how the reliability of learned robot policies can be improved at deployment time through mechanisms that operate around them.
We examine several such mechanisms: (1) runtime failure detection and intervention, (2) data-centric interpretation of policy behavior and performance, and (3) composition and coordination of learned behaviors for real-world, long-horizon tasks.
Contextual Graph Representations for Task-Driven 3D Perception and Planning Christopher Agia, Florian Shkurti Division of Engineering Science, University of Toronto, 2020 | Toronto, CA
arXiv
This thesis tests the suitability of existing embodied AI environments for research at the intersection of robot task planning
and 3D scene graphs and constructs a benchmark for empirical comparison of state-of-the-art classical planners.
Furthermore, we explore the use of graph neural networks to harness invariances in the relational structure of planning domains
and learn representations that afford faster planning.
Patents
Several components of my industry research projects were patented alongside submitting to conference / journal venues.
Systems and Methods for Generating a Road Surface Semantic Segmentation Map from a Sequence of Point Clouds Christopher Agia, Ran Cheng, Yuan Ren, Bingbing Liu
Application No. 17/676,131. Patent No. 12,008,762. U.S. Patent and Trademark Office, 2022
Google Patents
Relates to processing point clouds for autonomous driving of a vehicle. More specifically, relates to processing a sequence of point
clouds to generate a birds-eye-view (BEV) image of an environment of the vehicle which includes pixels associated with road surface labels.
Methods and Systems for Semantic Scene Completion for Sparse 3D Data Ran Cheng*, Christopher Agia*, Yuan Ren, Bingbing Liu
Application No. 17/492,261. Patent No. 12,079,970. U.S. Patent and Trademark Office, 2022
Google Patents
Relates to methods and systems for generating semantically completed 3D data from sparse 3D data such as point clouds.
Software Engineering Intern Microsoft, Mixed Reality and Robotics
May 2021 - Aug 2021 | Redmond, Washington
Research & development at the intersection of mixed reality, artificial intelligence, and robotics.
Created a process unlocking the training and HL2
deployment of multi-agent reinforcement learning scenarios in shared digital spatial-semantic representations with
Scene Understanding.
Research in artificial intelligence and robotics. Topics include task-driven perception via learning map representations for downstream
control tasks with graph neural networks, and visual state abstraction for Deep Reinforcement Learning based self-driving control.
Software Engineering Intern Google, Cloud
May 2020 - Aug 2020 | San Francisco, CA
Designed a Proxy-Wasm ABI Test Harness and Simulator that supports both
low-level and high-level mocking of interactions between a Proxy-Wasm extension and a simulated host environment,
allowing developers to test plugins in a safe and controlled environment.
Machine learning and robotics research on the topics of Visual SLAM and Deep Reinforcement Learning in collaboration with the Mobile Robotics Lab.
Deep Learning Research Intern
Huawei Technologies, Noah's Ark Research Lab
May 2019 - May 2020 | Toronto, ON
Research and development for autonomous systems (self-driving technology). Research focus and related topics: 2D/3D semantic scene completion,
LiDAR-based segmentation, road estimation, visual odometry, depth estimation, and learning-based localization.
Developed a state-of-the-art deep learning pipeline for real-time 3D detection and tracking of vehicles, pedestrians and cyclists from multiple sensor input.
Search and rescue robotics - research on the topics of Deep Reinforcement Learning and Transfer Learning for autonomous robot navigation in rough and
hazardous terrain. ROS (Robot Operating System) software development for various mobile robots.
Software Engineering Intern
General Electric, Grid Solutions
May 2017 - Aug 2017 | Markham, ON
Created customer-end software tools used to accelerate the transition/setup process of new protection and control systems upon upgrade.
Designed the current Install-Base and Firmware Revision History databases used by GE internal service teams.
“Give the pupils something to do, not something to learn;
and the doing is of such a nature as to demand thinking; learning naturally results.” - John Dewey
I've worked on a number of exciting software, machine learning, and deep learning projects.
Their applications cover a range of industries: Robotics, Graphics, Health Care, Finance, Transportation, Logistics, to name a few!
The majority of these projects were accomplished in teams!
The results also reflect the efforts of the many talented individuals I've had the opportunity to collaborate with and learn from over the years.
Links to the source code are embedded in the project titles.
Instruction Prediction as a Constructive Task for Imitation and Adaptation
Stanford University, CS330 Deep Multi-task and Meta Learning
Can natural language substitute as abstract planning medium for solving long-horizon tasks when obtaining
additional demonstrations is prohibitively expensive? We show: (a) policies trained to predict actions
and instructions (multi-task) improves performance by 30%; (b) policies can be adapted to novel tasks
(meta learning) solely from language instructions.
Project report /
Poster
Controllable and Image-Free StyleGAN Retraining for Expansive Domain Transfer
Stanford University, CS348i Computer Graphics in the Era of AI
StyleGAN has a remarkable capacity to generate photrealistic images
in a controllable manner thanks to its disentangled latent space. However, such architectures can be difficult
and costly to train, and domain adaptation methods tend to forego sample diversity and image quality. We prescribe a set
of ammendments to StyleGAN-NADA which improve on the pitfalls of text-driven
(image-free) domain adaptation of pretrained StyleGANs.
Project report /
Presentation
Bayesian Temporal Convolutional Networks
University of Toronto, CSC413 Neural Networks and Deep Learning
In this project, we explore the application of variational inference via Bayes by Backprop to the increasingly
popular temporal convolutional networks (TCNs) architecture for time series predictive forecasting.
Comparisons are made to the effective state-of-the-art in a series of ablation studies.
Project report
SfMLearner on Mars
University of Toronto, ROB501 Computer Vision for Robotics
3D Shape Reconstruction
University of Toronto, APS360 Applied Fundamentals of Machine Learning
An empirical study of various 3D Convolutional Neural Network architectures for predicting the full voxel geometry of objects given their partial signed distance
field encodings (from the ShapeNetCore database).
Project report
Designed, built, and programmed a robot that systematically sorts and packs up to 50 pills/minute to assist those suffering from dimentia.
An efficient user interface was created to allow a user to input packing instructions. Team placed 3rd/50.Detailed project documentation /
Youtube video
Based on the robotics Sense-Plan-Act Paradigm, we created an AI program
to handle high-level (path planning, goal setting) and low-level (path following, object avoidance, action execution) tasks for an
automated waste collection system to be used in fast food restaurants. 4th place Canada.Presentation
Developed a machine learning software solution to predict the triage score of emergency patients, allocate available resources to
patients, and track key hospital performance metrics to reduce emergency wait times. 1st place Ontario.Presentation / Team photo
Created a logistics planning algorithm that assigned mobile robots to efficiently retrieve warehouse packages. Our solution combined
traditional algorithms such as A* Path Planning with heuristic-based clustering. 1st place UofT.Presentation / Team photo
Smart Intersection - Yonge and Dundas
University of Toronto, MIE438 Robot Design
We propose a traffic intersection model which uses computer vision to estimate lane congestion and manage traffic flow accordingly.
A mockup of our proposal was fabricated to display the behaviour and features of our system.
Detailed report /
YouTube video
Created a simulator that ranks the performance of any solar array CAD model by predicting the instantaneous energy generated under various daylight conditions.
Developed an AI program capable of playing Gomoku against both human and virtual opponents. The software's decision making process
is determined by experimentally tuned heuristics which were designed to emulate that of a human opponent.
Programmed an intelligent system that approximates the semantic similarity between any two pair of words by parsing data from
large novels and computing cosine similarities and Euclidean spaces between vector descriptors of each word.


















{kind=link}
{kind=link}